
Source : https://archive.org/details/C64DatabarOSCARSoftware.
Qu’il s’agisse de bibliographie non empruntable, d’archives ou d’extraits de documents, il est souvent utile de procéder à une numérisation de documents. Quelques outils et « trucs » pour le faire.
Scanner avec son smartphone
La plupart des étudiants utilisent leur smartphone pour procéder à des numérisations rapides un peu partout. Pour les grands documents (exemple : plans papiers), un appareil photo est nécessaire. Mais pour des formats inférieurs au A4, l’utilisation du smartphone peut suffire. Voici des applications qui reconnaissent les bords de document, et évitent d’avoir des photos avec des marges (bords de livre, table, etc.).
Android : Des Applications sans incitation à l’achat, adaptées pour des textes
vFlat
Plusieurs fonctions permettent de corriger les défauts liés à la prise de vue et ainsi faciliter la reconnaissance de caractères (qui permet de transformer une image en texte) ultérieure :
- détecte immédiatement les bords de documents ;
- corrige la courbure optique liée à la déformation de l’objectif ;
- aplatit les images ;
- supprime les doigts en bord de page ;
- si l’on choisit « tableau blanc » au moment de la prise de vue, le logiciel renforce immédiatement le contraste pour avoir un fond blanc et des lettres noires.
Le logiciel propose en plus, en cas de connexion 4G ou en Wifi d’effectuer une reconnaissance de caractères efficace, et d’exporter un livre avec plusieurs pages en .pdf avec un texte éditable. Attention : cela prend de la ressource. Il est très souvent préférable d’effectuer ce type d’opération sur son ordinateur dans un deuxième temps.
Microsoft Office Lens
Trois fonctions facilitent la reconnaissance de caractères ultérieure :
- détecte immédiatement les bords de documents ;
- corrige les déformations liées à la prise de vue ;
- si l’on choisit « tableau blanc » au moment de la prise de vue, le logiciel renforce immédiatement le contraste pour avoir un fond blanc et des lettres noires.
Le logiciel permet aussi de transformer l’image ainsi obtenue en document word, mais cela ne peut être fait que ponctuellement, car le temps de traitement est long. Pour des questions d’efficacité, il est préférable de le faire après coup, sur son ordinateur.
Nettoyer ses photos de texte : Scantailor advanced
Avant de chercher à convertir des photos de textes en texte modifiable, il est largement préférable de les nettoyer :
- les mettre en noir et blanc ;
- les retourner pour que les lignes de texte soient horizontales (deskew en anglais) ;
- permettre la reconnaissance automatique (ou le choix manuels) des blocs de textes et d’images ;
- enlever les déformations du texte liées à la perspective et aux pages « bombées » ;
- nettoyer les marges autour du texte, etc.
Toutes ces fonctions sont possibles sur une série d’images avec ScanTailor Advanced.
Corriger l’orientation de la page

Séparer les pages de droite et de gauche

Corriger les éventuelles déformations du scan
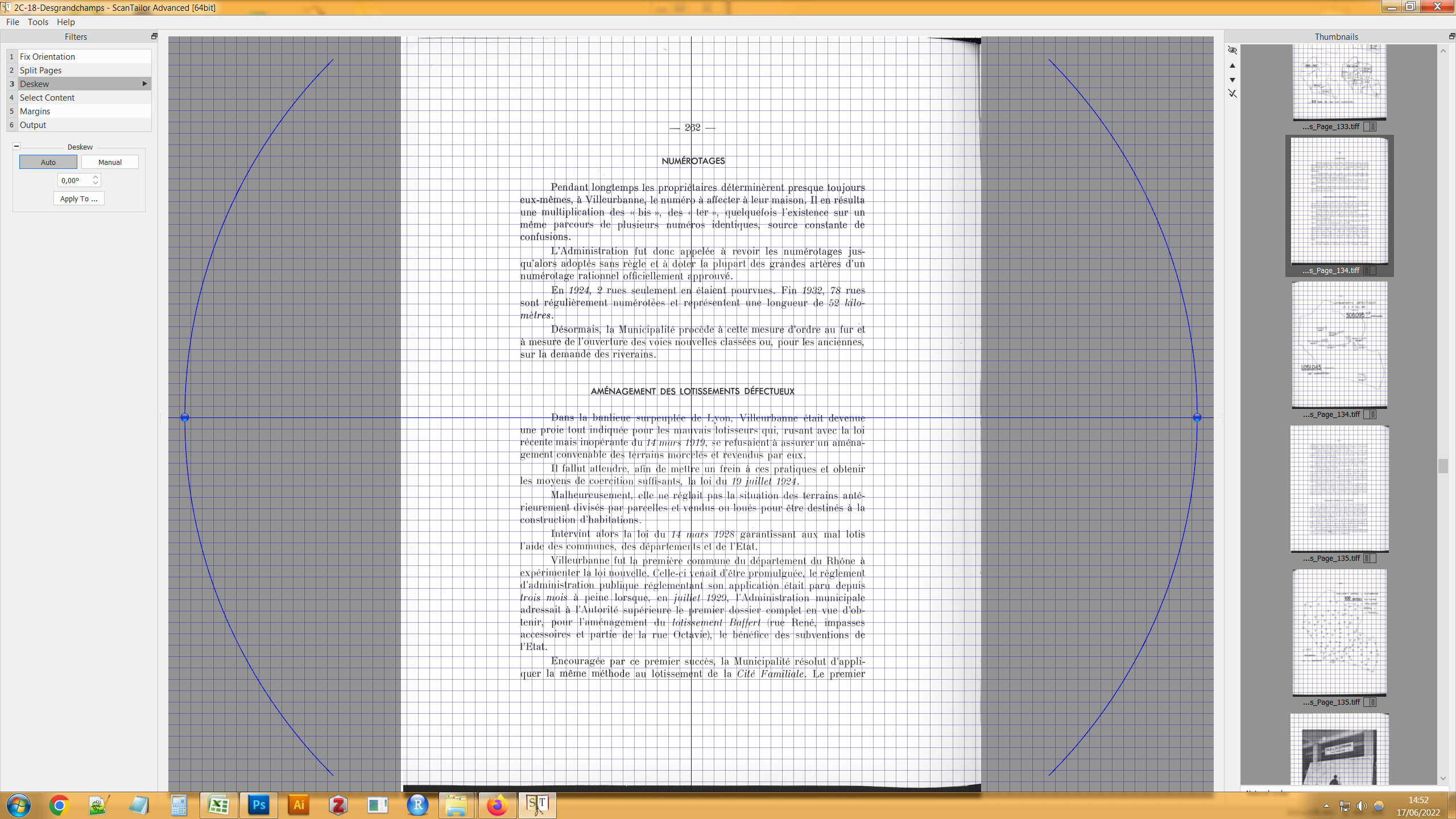
Détecter le contenu de la page (sans les marges)

Détecter les marges blanches dans la page

Exporter vers un fichier

Transformer des images en texte : « océriser »
La reconnaissance optique de caractères permet de transformer un scan de texte nettoyé en texte éditable dans un logiciel de traitement de texte (LibreOffice Writer, Word, etc.). De nombreux logiciels existent sur le marché, mais les plus performants sont le plus souvent payants, et chers. Pour contourner ce problème, quelques solutions existent.
Tesseract
C’est un moteur de reconnaissance optique de caractères (OCR) qui est utilisé par de nombreux logiciels ou plateforme en ligne. On peut l’utiliser directement en lignes de commande, mais c’est assez fastidieux. Il faut toutefois souvent l’installer avant d’installer un logiciel de reconnaissance de textes performant. Dans certains cas, il s’installe en même temps.
Installer la dernière version de Tesseract pour Windows, en cours de développement par la bibliothèque universitaire de Mannheim.
Manuel de l’utilisateur
Attention : au moment de l’installation, il est important de choisir les langues que l’on souhaite installer. En effet, la reconnaissance de caractères ne fonctionne bien que dans une langue. Un exemple : le « oe » est souvent collé en français, le logiciel doit pouvoir le reconnaître.
gImageReader
gImageReader est un logiciel qui fait appel à Tesseract. Il faut avoir d’abord installé Tesseract pour le faire fonctionner. Fonctionnalités :
- traite images et fichiers PDF ;
- acquisition depuis scanner ;
- sélection des parties de l’image à traiter ;
- récupère une image depuis le presse papier (utile pour les captures d’écran) ;
- supporte différentes langues ;
- comparaison cote à cote de la source et du résultat ;
- supprime les saut de lignes dans le texte résultant ;
- prise en charge des dictionnaires ;
- lecture des lignes tordues.
Attention !
- Ce logiciel fonctionne bien, mais sur des images de textes propres (sans bord, avec un bon contraste entre le texte et le fond). Il est important de vérifier la qualité des numérisations avant de commencer la reconnaissance de texte. Sinon, les résultats sont décevants.
- Il est important de travailler dans la langue du document, c’est ce qui conditionne une bonne reconnaissance du texte par le logiciel.
Si ces deux conditions sont réunies, le logiciel est très performant !